
Resources
Sequence Similarity: An inquiry based and "under the hood" approach for incorporating molecular sequence alignment in introductory undergraduate biology courses
Author(s): Adam Kleinschmit1, Benita Brink1, Steven Roof2, Carlos Christopher Goller3, Sabrina Robertson3
1. Adams State University 2. Fairmont State University 3. North Carolina State University
4791 total view(s), 830 download(s)
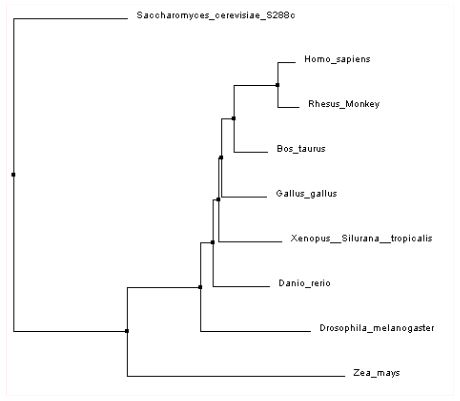
Description
Introductory bioinformatics exercises often walk students through the use of computational tools, but often provide little understanding of what a computational tool does "under the hood." A solid understanding of how a bioinformatics computational algorithm functions, including its limitations, is key for interpreting the output in a biologically relevant context. This introductory bioinformatics exercise integrates an introduction to web-based sequence alignment algorithms with models to facilitate student reflection and appreciation for how computational tools provide similarity output data. The exercise concludes with a set of inquiry-based questions in which students may apply computational tools to solve a real biological problem.
In the module, students first define sequence similarity and then investigate how similarity can be quantitatively compared between two similar length proteins using a Blocks Substitution Matrix (BLOSUM) scoring matrix. Students then look for local regions of similarity between a sequence query and subjects within a large database using Basic Local Alignment Search Tool (BLAST). Lastly, students access text-based FASTA-formatted sequence information via National Center for Biotechnology Information (NCBI) databases as they collect sequences for a multiple sequence alignment using Clustal Omega to generate a phylogram and evaluate evolutionary relationships. The combination of diverse, inquiry-based questions, paper models, and web-based computational resources provides students with a solid basis for more advanced bioinformatics topics and an appreciation for the importance of bioinformatics tools across the discipline of biology.
CourseSource Citation
Kleinschmit, A., Brink, B., Roof, S., Goller, C., and Robertson, S.D. 2019. Sequence Similarity: An inquiry based and “under the hood” approach for incorporating molecular sequence alignment in introductory undergraduate biology courses. CourseSource. https://doi.org/10.24918/cs.2019.5
Notes
- Exercise Format
- The single composite learning resource has been split out into multiple stand-alone modular exercises
- Each modular exercise, student thought question worksheet, necessary FASTA sequences, and instructor’s solution key have been bundled into a single document along with a preface page with implementation instructions for the instructor
- The goal of the updated exercise format is to allow for effortless implementation of subsections over multiple class sessions and to encourage implementation of select subsections that best align with course learning objectives for instructors that would like to use a subset of the modules
- Copy edits and minor text choice modifications
- Exercise title change to mirror the associated CourseSource manuscript by Kleinschmit et al., 2019
Reference
Kleinschmit, A., Brink, B., Roof, S., Goller, C., and Robertson, S.D. 2019. Sequence Similarity: An inquiry based and “under the hood” approach for incorporating molecular sequence alignment in introductory undergraduate biology courses. CourseSource. https://doi.org/10.24918/cs.2019.5
Cite this work
Researchers should cite this work as follows:
- Adam Kleinschmit, Benita Brink, Steven Roof, Carlos Christopher Goller, Sabrina Robertson (2019). Sequence Similarity: An inquiry based and "under the hood" approach for incorporating molecular sequence alignment in introductory undergraduate biology courses. NIBLSE Incubator: Bioinformatics - Investigating Sequence Similarity, (Version 5.0). QUBES Educational Resources. doi:10.25334/Q4G45Z